
1. Introduction
This report describes how autonomous vehicles deal with big data scenarios and what the proper database management systems are suited for the autonomous vehicles. Analysis has been done with different subtopics to make a critical decision between SQL and NoSQL.
2. Analysis
2.1. Dataset types, data characteristics and data sources
2.1.1. Autonomous Vehicles with big data
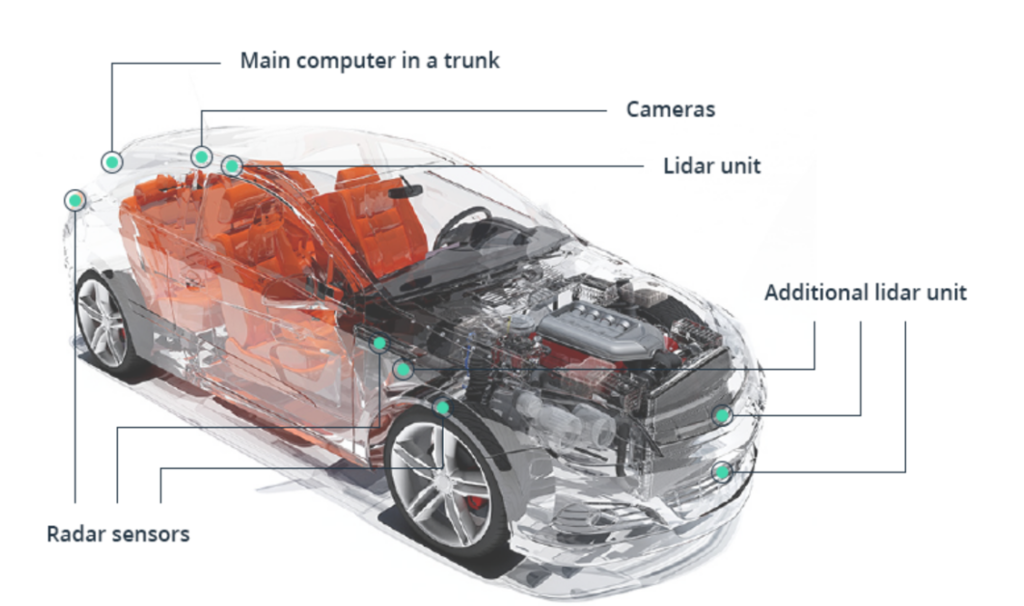
Autonomous vehicles (AV) deal with several data types such as radar, lidar, IOT, GPS, sensor data, video cameras, images, odometry and ultra-sonic data. It is generally considered that there are two subsets of data which are related with static and dynamic environment. These data sets can be easily defined by using semantic map. It is one of the powerful tools for planning and problem predictions of autonomous vehicles. It is consisted with different types of attributes such as speed limits, physical positions of traffic lights, stop signs, crosswalks, weather data, lines of the road and parking zones.
Intel indicates that an autonomous vehicle itself gets 4000 GB data per day. Data is collected by various types of sources with different volumes as follows. (Per second)
- Cameras – ~ 20-40 KB
- Radar – ~ 10-100 KB
- Sonar – ~ 10-100 KB
- GPS – ~ 50 KB
- Lidar – ~ 10-70 KB
Each task of above sources can be identified as follows.
- Cameras – recognising moving obstacles like pedestrians and bicycles.
- Radar – Detecting dangerous objects far away from more than 100 meters
- Sonar -Detecting large objects which are made of solid materials at short distances.
- GPS – Tracking the position of vehicle with the accuracy of 30 centimetres tolerance.
- Lidar – Scanning environment with lasers by 3600
2.1.2. Comparison:
SQL databases store data in a vertical structure that is based on rows and columns. NoSQL is scaled with a horizontal structure, and it helps to increase the performance and scalability as needed. Further it avoids complexity of SQL queries and ACID (Atomicity, Consistency, Isolation, Durability) transactions. As mentioned above an autonomous vehicle takes huge and various types of data and normally generates more than 20 TB per day. So, when handling these types of data that is consisted with high volume and variability from SQL, there may be designing problems, poor written queries and data with lots of joins. Nevertheless, NoSQL databases like Apache Spark, MongoDB, CouchDB and Cassandra are few examples that can be used to achieve those problems in autonomous vehicle.
2.2. Data processing and storage requirements
2.2.1. Life Cycle of an autonomous vehicle
When considering about the process of an autonomous vehicle, it can be categorized in to three steps as follows.
- Testing and validation
- Data storage
- Research and development
As the first step, an autonomous vehicle needs to identify all the objects near to the vehicle. Different types of simulation techniques and real-world driving scenarios are considered in the testing and validation stage. Here, testing methods like functional test, interface test, fault injection, resource usage performance test and scenario-based test are used in the testing step. When it comes to validation part, different types of validation techniques are used to ensure safely and reliably. Some of them are simulation environment with MIL, HIL, VIL models, FMEA and FTA.
As the second step, petabytes of sensor and simulation data will be stored in data storages. Here, data will be stored in each chunk in order to analyse data easily. In the research and development stage, new algorithms and functions are used to process and analyse data. Many autonomous vehicle companies use robot operating system (ROS) to easily access, analyse and visualize data. For instance, there are many pre-defined codes and algorithms which are required to identify obstacles, GPS path and to decide the optimal route. As well as it provides graphical and visualization tools which can easily take data from sensors.
2.2.2. Comparison:
When implementing data of an autonomous vehicle, various types of data need to be processed. SQL processes relational data with tables by linking tables together logically. Even though it is a good managing system, it is hard to scale and maintain data because of high cost when it comes to big data. It is very hard to proceed normalization, defining schemas and relations when there is large amount of data with SQL. NoSQL databases split data into partitions and each partition can be mirrored across multiple servers which means server can go down without much impact. It can run even millions of queries in a second. Further, it is consisted with key-value based system and items of the database do not need to be structured which means schemeless. There are four types of NoSQL.
- Key-Value – has a great potential for horizontal scaling. (Redis, DynamoDB)
- Document Oriented -Document based structure to store hierarchical data. (CouchDB, MongoDB)
- Graph – mainly consisted with nodes and edges. (Neptune, Neo4j, AllegroGraph)
- Column Oriented -Well suited for faster query process with large data. (Cassandra)
Moreover, Sensors are capturing different types of data while seeing obstacles like birds, other vehicles, buildings etc. So, it is a huge problem to gather all these data to one platform. Therefore, Apache Hadoop platform has been introduced to process large amount of data in an efficient, reliable scalable way. Hadoop Distribution File System (HDFS) which is used to store data, is provided by Hadoop.
2.3. Organisation readiness and affordability
It is significant for organization to focus affordability while choosing optimal data base. Even though SQL simply manipulates data within relational diagrams, it is not suitable when there are various and large amount of data as mentioned above. Organization should consider about the characteristics of big data (4 V s) before selecting the best database system.
1. Volume
There are different ways to handle large volume of data by using NoSQL as follows.
- Even Distribution of Data
Data can be evenly distributed by using hash ring method and hash value helps to determine which nodes that data should be assigned.
- Replication
As data is generated in real time back up files are generated with replication.
- Queries need to be moved to data
Data can be kept in nodes and only the results can be transferred to the network. Then transferring process will be taken place quickly.
When it comes to SQL servers, normally backup time would be around five to seven hours for 10 TB file even using a better hardware. Re-organizing is the only way to maintain large amount of data in SQL servers and it takes more time to rebuild index on big tables.
2. Velocity
An autonomous vehicle should capture fast moving data very quickly. Column-based and key-value types have been introduced related to the NoSQL in order to process big data in a short period of time. Redis, Memcached, Cassandra, HBase and Hyper table can be taken as examples. SQL shows less performance while generating data compared with NoSQL.
3. Variability
Document-based databases play a major role when there is high variability of data. MongoDB and CouchDB can be mentioned as the examples. SQL needs complex design structures to handle high variability issues.
4. Veracity
It simply means to what extent data is consistent and trustworthy how data is stored and retrieved accurately. Further it tells that horizontal scaling are more likely to have high veracity than vertical scaling which means NoSQL is better than SQL.
2.4. Data quality requirements – consequences/drawbacks of low-quality datasets
There is a consensus that the data quality is normally depended on the nature of the data source. There are some data qualities dimensions (DQD) such as accuracy, timeliness, consistency and completeness. Moreover, there are some factors which help to make good models.
1. non-Redundancy
When there are many duplicate values, more storage space is required for the data.
2. Data reusability
Data must be independent and appropriately arranged. There should be a proper checking method to identify whether the stored data can be reusable or not.
3. Stability and Flexibility
When there are little changes or none, the model is stable. It is flexible if it can be expanded to accommodate certain new requirements with just minor effects.4. Elegance
Model should provide neat and simple classification of the data and it should be easily described and summarized.
5. Integration
The proposed databases should be integrated with existing and future databases.
Hadoop file system is consisted with numerous nodes to avoid catastrophic issues and increase the replication. Nevertheless, researchers need to focus more regarding the quality measurements for unstructured data, schema-less data and the development of real time dashboards for quality monitoring as well.
2.5. Knowledge retrieval, analytics or decision support requirement
Nowadays, System designers focus scaling out (Horizontal scaling) than scaling up (Vertical scaling) to increase efficiency and capacity. NoSQL (Column-Oriented) databases have capability to handle structured, semi-structured and unstructured data than SQL. SQL databases need more powerful hardware like CPU, RAM and SSD to scale up in order to handle large amount of data in autonomous vehicles and additional investment needs to be spent. Further less processing time, high accuracy, better simulation and less expensive can be considered as some benefits of using NoSQL than SQL.
2.6. Data privacy and security issues
SQL injection attacks can be taken place when there is inadequate input validation process of user interface. In order to fix these issues some strategies have been introduced like anomaly detection and SQL-IDS (SQL Injection Detection System). But high computational overhead cost is one of the main disadvantages of these approaches. Other method is that visualization of queries that can be classified related to the colours. Thereby legal queries, non-recovered queries and attacks can be identified related to specific colours. Developers uses security systems such as classic cryptography mechanisms and encryption protocols, homomorphic encryption, digital signature schemes, bilinear maps and discrete logarithm to ensure data confidentiality and to secure communication. Crash recovery systems have been introduced to face online analytical processing (OLAP) or data mining processes for SQL data bases to ensure durability and transaction atomicity.
Data integrity of SQL databases is kind of component of information and security which refers accuracy, consistency and completeness of data.
1. Domain Integrity
Domain Integrity can be described by unique data type such as character, integer or decimal. But the values of the column should be related with one data type. If default value is not specified for a column definition NULL can be used.
2. Entity Integrity
It ensures that each row in a table should be uniquely identified. Primary key enforces entity integrity which means it does not allow for duplicate values and NULL
3. Referencial Integrity
It is concerned with the maintenance of relationship between the tables. Rule of referential integrity ensures that a non-value of a foreign key must be within the domain of the related primary and unique key. It requires whenever the foreign key is used which means each row should be associated record.
4. User Integrity
covers all other forms of integrity constraints that are not covered by the other three.
NoSQL databases consider several security threats such as authentication, distributed environment and fine-grained authentication. Kerberos is used to authenticate clients and nodes data can be grouped according to the security level to ensure fine-grained authentication. For instance, Cassandra uses TDE (Transparent Data Encryption) technique to protect sensitive data. NoSQL datastores have implemented some solutions such as pseudonyms-based communication network, monitoring, filtering and blocking scenarios to ensure privacy and security.
1. Pseudonyms-based communication network
In this scenario, users can access multiple servers by using only one credential.
2. Monitoring, filtering and blocking
There are some techniques like authentication via Kerberos and second level authentication to access map reduce.
As a summary of data integrity of NoSQL, fundamental ideas and concepts required can be mentioned for our approach’s implementation and analysed in this part as follows.
- Hash function – Collision-resistant hash function which has the feature that finding two inputs that hash to the same output.
- Two secret keys – One for data encryption and another for data authenticity. (For data owner and clients)
- Data Authentication – The Data owner digitally authenticates its data using a MAC (Message Authentication Code) method and stores the MAC value alongside the digitally authenticated data in the cloud. Then data authentication can be verified to the clients based on MAC.
When comparing SQL and NoSQL there is a same probability to have threats from external environment, but NoSQL has bit less security features unlike SQL.
3. Conclusion
According to the analysis which has been done above with different subtopics, it describes that both SQL and NoSQL databases have pros and cons when handling large amount of data related to the autonomous vehicles. Finally it concludes that NoSQL sources are more likely to handle big data and achieve critical scenarios of autonomous vehicles than SQL.